쿠팡 알고리즘

모델 중심의 플랫폼에서 서비스와 모델을 분리하는 플랫폼으로 변화
과거 쿠팡 알고리즘: 단일 모델 혹은 복수 모델이 상품 추천의 모든 역할을 수행
현재 쿠팡 알고리즘: 서비스가 모델로부터 독립되어, 모델은 Feature만 추출하고 서비스가 그 결과들을 기반으로 상품 추천을 수행
그 결과, 모델은 단순해지고 서버는 복잡해졌다고 할 수 있습니다.
모델은 Feature를 추출하는 역할만 할만큼 단순해졌으나 대신 서버 측에서 파라미터 튜닝 모델 학습 등이 중요합니다.
이렇게 할 경우 다음과 같은 장점이 있습니다.
1) 빠른 서비스 개발, 피처와 가중치 등 조합에 따른 새로운 서비스 개발 가능
2) 만들어 놓은 Feature를 다른 서비스에서도 응용하여 사용 가능
3) 서비스 문제가 생기더라도 query를 tuning해서 문제 해결 가능
인공지능 추천 시스템 쿠팡 알고리즘 전체 시스템

모델
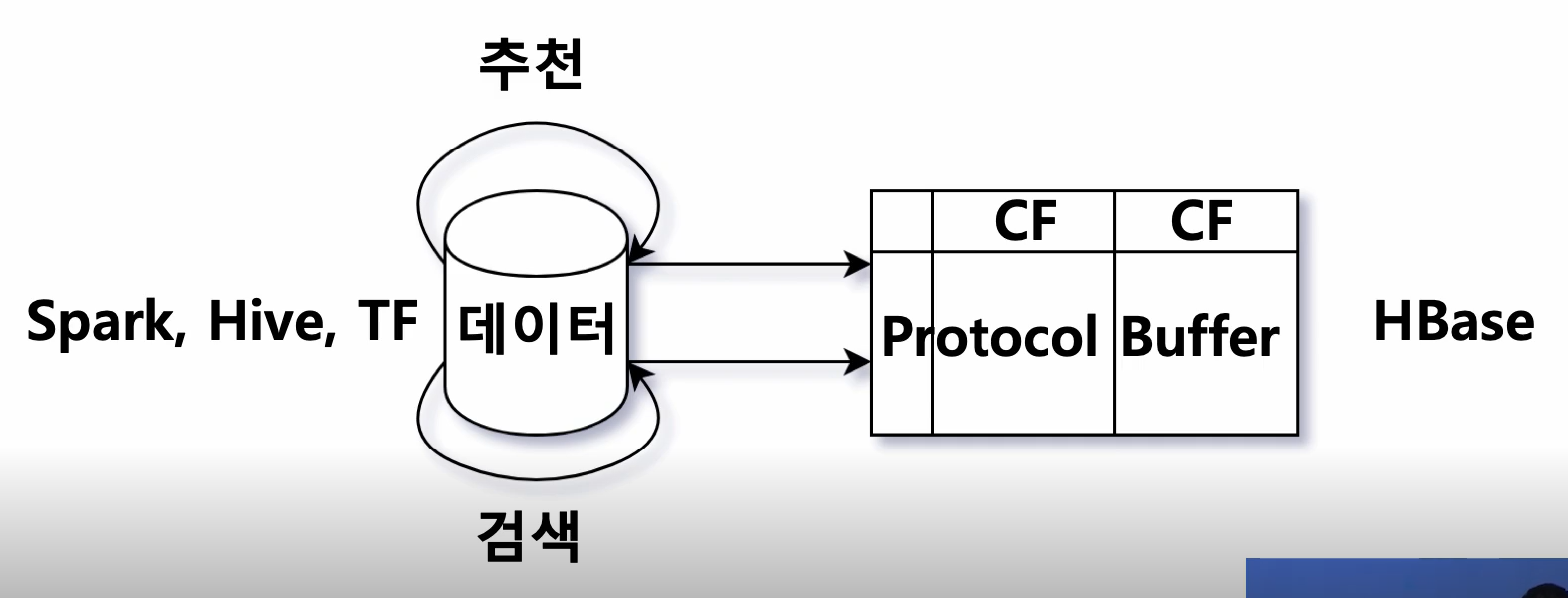
- 모델은 Spark, Hive, TF 등을 활용해 데이터의 Feature를 추출
- 추출한 Feature는 Protocol Buffer(구글에서 만든 직렬화(Serialization)된 데이터 구조)의 형태로 HBase에 저장
쿠팡의 Protocol Buffer

1) Product라는 메시지를 정의해서 관리
2) 상품 그 자체가 갖는 feature인 image, category, rating, 리뷰 수 등의 정보 있음
3) 이 상품이 다른 어떤 상품에 몇 점의 점수로 추천 할 수 있는지를 반복 필드(?)로 두고 있음
4) 쿠팡 search팀에서 관리하는 정보, 추천팀에서 관리하는 정보가 서로 다른 column family에 들어있기 때문에 인덱싱 할 때에는 Protocol Buffer의 mergeFrom API를 사용해 merge해서 사용합니다.
Search Cluster에서는 컨텍스트(유저, 아이템, 시간, 카테고리)와 관련된 상품을 찾고, 조건에 따라 필터를 한 다음 점수에 따라 정렬합니다.
근데 모델에서 만드는 feature의 수는 계속해서 많아집니다. 이럴수록 어떤 feature에 얼마만큼의 가중치를 줘야하는지 결정해야 하는 문제가 생긴다. 이러한 작업을 사람의 손에 맡기는 것은 효율성이 낮습니다.
이 작업을 컴퓨터가 할 수 있도록 쿠팡에서 도입한 것이 LTR입니다. 즉, 쿼리 튜닝을 컴퓨터에게 맡기기 위해 사용하는 것입니다.
LTR을 학습시키기 위해서는 어떤 상품이 어떤 feature를 가지고 추천되었는지 알아야 하며, 반응이 어땠는지도 알아야 합니다. 그래서 쿠팡의 서버에서는 추천 상품을 내보낼 때 마다 해당 상품이 어떤 feature를 가지고 있었는지 logging합니다. 또한 해당 상품이 어떤 session id에, 어떤 search id에 추천되었는지도 기록되어야 합니다.
컨텍스트를 정의하는 것이 Query Handler Cluster입니다.(=서비스를 정의한다.) 예를 들어, “냄비와 함께 살 만한 할인상품”이라는 추천을 하고 싶다면, bought_together에 “냄비”가 들어있는 상품을 Query하고, category를 “식품”으로 필터링합니다. 또한 discount_rate로 부스팅까지 하면 됩니다. 이 때 Customer Feature를 사용해서 개인화된 서비스를 정의하기도 합니다.
Feature Selection
모든 피처를 사용하는 것이 성능이 더 좋을 수는 있습니다. 하지만 쿠팡에서는 피처의 수를 적게 유지하도록 노력한다고 합니다. 그 이유는 피처가 많다면 새로운 피처를 넣었을 때 어떻게 영향을 미치는지 파악하기 어렵고, 어떤 것을 먼저 개선해야 하고, 디버깅해야 하는지 파악하기가 힘들기 때문입니다.
좋은 feature를 선택하기 위해서 모델이 어떤 feature를 중요하게 여기는지 분석하기도 하고, feature 간의 상관관계를 따져 상관관계가 높은 feature는 삭제합니다.
Raw Feature vs Processed Feature
쿠팡은 Processed Feature를 사용합니다.
Raw Feature를 사용하면 각 feature가 모델에 어떻게 영향을 미치는지는 비교적 쉽게 이해할 수 있지만, 상관관계가 높은 feature가 여러 개 남을 수 있다고 합니다. 처음 LTR 모델을 도입할 때는 Raw feature를 사용하되 시간이 지나면 상관관계가 높은 feature를 제거한 processed feature를 사용하는 것이 바람직합니다.
복잡한 LTR 모델(RNN, CNN) vs 단순한 LTR 모델(Decision tree, MLP)
쿠팡은 굉장히 단순한 모델 채택(Decision tree)

이유
1) 각 픽셀의 RGB 값이 모두 feature가 되는 이미지와 달리 상품 추천 영역에서는 feature의 수가 굉장히 적은 편입니다.
2) 복잡한 모델을 사용해서 오프라인 평가를 좋게 받더라도 유저의 반응이 그 만큼 좋으리라는 보장이 없습니다.
피처 엔지니어링 vs 파라미터 튜닝
쿠팡은 피처 엔지니어링 선호
파라미터 튜닝을 이것저것 시도를 해보고 있지만, 어떤 파라미터가 왜 잘 작동하는지 이해하기 어렵습니다. 그보다는 새로운 feature를 만들고, 그 feature가 모델에 어떤 영향을 미치는지 파악하는 것이 중요합니다.
쿠팡 개발자 님의 쿠팡 알고리즘에 관련된 Q&A
1. 새로 들어온 유저에 대해서는 어떻게 대응하는가?
들어와서 상품을 보기 시작하면서 정보가 쌓이기 시작한다. 이것이 최종적으로 유저의 선호를 결정하는 것은 아니기 때문에 초기 유저의 선호는 자주 바뀐다. 따라서 추천되는 상품 등도 자주 바뀌게 된다.
2. 추천 시스템 평가 방법
서비스 개발 주기가 굉장히 빨라서 offline 평가는 크게 신경쓰지 않는다. A/B테스트를 바로 진행하며, 그 결과로 의사결정을 한다.
3. DBMS는 어떤 것 사용하는가?
분산 HDFS(Kafka)에 저장 => 하이브에 저장 => 스파크나 하이브SQL 등 작업자가 선호하는 방법으로 꺼내 쓴다.
4. A/B테스트 검증은 어떻게?
p-value
5. A/B테스트 샘플군은 어떻게 정하나?
정하지 않는다. 전체 유저를 반으로 잘라 테스트한다.
6. A/B테스트를 하는 타이밍
모델이나 feature를 하나 만들고 난 후 즉시 수행. 성능이 안좋으면 바로 폐기
7. 유저가 들어올 때 마다 매번 같은 추천 상품을 노출하는가?
No. random 함수를 사용해 매번 다른 상품 노출
(참고 및 출처:
)
좋은 정보 제공해주셔서 감사합니다 :)
2021.03.29 - [테크 큐레이터] - [테크] 인스타 스토리 조회 순서, 방문자 순서 알고리즘 어떻게 구성될까? | 쿠팡 알고리즘 A to Z
2021.01.18 - [테크 큐레이터] - [테크] 테슬라가 이끄는 모빌리티 혁명 | 애플을 뛰어넘는 테슬라 | 세계 부호 1위 일론 머스크 CEO
2021.03.26 - [테크 큐레이터] - [테크] 데이터 정합성 | 데이터 무결성 | Data Integrity 정의 및 차이점 총정리




댓글